Origen y parentesco de las lenguas de Eurasia
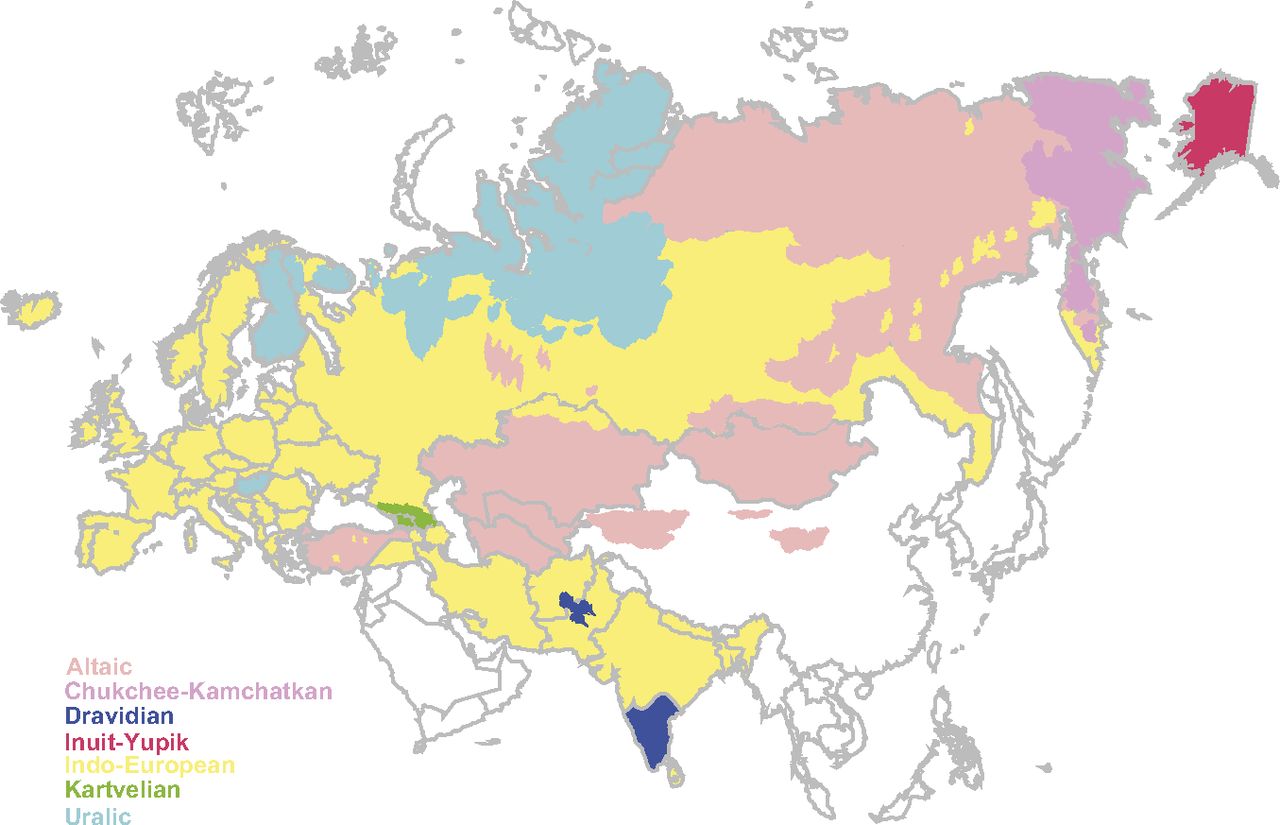
Mapa en que se muestra las regiones en las que se hablan las lenguas de las siete familias lingüísticas de Eurasia
Aunque hasta ahora se había puesto muy en duda que fuera posible, parece que se pueden establecer relaciones de parentesco entre lenguas que divergieron hace miles de años, a partir de las semejanzas existentes entre algunas palabras que se han conservado con pocas variaciones a lo largo del tiempo. Esa posibilidad se basa en que las palabras que comparten origen común mantienen alguna similitud, siempre que no hayan cambiado demasiado.
El grado de similitud entre palabras es un criterio que se ha utilizado desde hace tiempo para establecer relaciones de parentesco entre lenguas. Sin embargo, es un método que tiene problemas. Por un lado, las palabras pueden cambiar muchísimo a lo largo del tiempo, y algunas muy especialmente, de manera que es fácil que aunque compartan un origen común, su relación llegue a ser indetectable. Y por otro lado, también puede ocurrir que se produzcan similitudes debidas al azar entre palabras que, de hecho, no guarden ningún parentesco.
Sin embargo, esos problemas pueden solventarse siempre y cuando se cumplan dos condiciones. La primera es que haya un grupo de palabras para las que la correspondencia entre sonido y significado se haya mantenido durante tiempos tan prolongados que perduran trazas de su origen incluso en lenguas que se separaron hace miles de años. Y la segunda es que esas palabras “ultraconservadas” puedan predecirse a priori y con independencia de las correspondencias de sonido con otras palabras. En relación con la primera condición, la mayor parte de las palabras tienen un 50% de probabilidades de ser sustituidas por otra palabra no “familiar” o no semejante, cada 2.000-4.000 años. Pero hay palabras, como los numerales, pronombres y ciertos adverbios, que son sustituidas cada más tiempo: esas palabras tendrían una probabilidad de un 50% de ser sustituidas cada 10.000, 20.000 o más años. Afortunadamente, a partir de elementos de información que son independientes de su sonido, se puede predecir qué palabras son esas con un alto grado de confianza. En efecto, la frecuencia con que son utilizadas las palabras permite predecir lo rápidamente que son reemplazadas por otras, de manera que se puede contar con un conjunto de palabras que se sustituyen con una probabilidad muy baja (las “ultraconservadas”) y para las que esa característica se ha podido establecer de forma independiente de su sonido, que era lo que se necesitaba. Y todo esto es válido para las lenguas pertenecientes a un amplio conjunto de familias lingüísticas, en el que se incluyen la indoeuropea, urálica, sino-tibetana, congo-nigeriana, altaica y austronesia.
Un estudio publicado recientemente ha dado cuenta de los resultados de una investigación realizada sobre esas bases conceptuales. En esa investigación se ha seleccionado un conjunto de palabras que, con alta probabilidad y por compartir origen común, se asemejan en alguna medida en las lenguas altaicas, chucoto-camchatcas, drávidas, esquimo-aleutianas, indoeuropeas, kartvelianas (caucásicas meridionales) y urálicas, familias que supuestamente forman parte de una superfamilia y cuya lengua antecesora común empezó a diferenciarse hace unos 15.000 años. A esas familias pertenecen casi todas las lenguas habladas hoy en Eurasia.
Los autores de la investigación referida recopilaron 200 protopalabras. Las protopalabras son palabras reconstruidas por lingüistas a partir de las palabras actuales, siguiendo un proceso “hacia atrás” y se encuentran recogidas en la base de datos etimológica mundial (LWED por sus siglas en inglés), que es parte del proyecto Torre de Babel. Lo que hacen los lingüistas es deducir cuál es la forma más probable de las palabras originarias de las que proceden las actuales, y para ello hacen comparaciones entre los sonidos de las palabras actuales y aplican a cada una de ellas las reglas de derivación que se conocen en cada lengua, con la particularidad de que esas reglas se aplican en la dirección contraria. Por ejemplo, las palabras frère (francés) y brother (inglés) comparten sonidos y significado, y en ambos casos se pueden aplicar las reglas conocidas de derivación de esas lenguas para deducir de qué otra palabra o palabras pueden proceder.
Las protopalabras escogidas fueron las que correspondían a los 200 significados de la lista de vocabulario fundamental de Swadesh, con la excepción de 12, para los que no se dispone de las correspondientes protopalabras. Por lo tanto, los investigadores trabajaron con 188 significados para los que se contaba con una o más de una protopalabra (porque en algunos casos puede haber más de una protopalabra para el mismo significado) reconstruida en al menos tres familias lingüísticas. A partir de ese punto, trataron de identificar las protopalabras que son cognadas, o sea, que aunque pertenecen a diferentes familias lingüísticas, están emparentadas y tienen cierta semejanza entre ellas, y estimaron el tamaño de cada clase de palabras cognadas. O sea, al agrupar las protopalabras supuestamente emparentadas de las distintas familias, podía resultar que una protopalabra no se asemejase a ninguna otra, lo que quería decir que el tamaño de la clase de las cognadas era de 1, o podían formarse grupos de hasta siete cognadas, porque son siete las familias lingüísticas estudiadas (tamaño = 7). El tamaño medio de clase de cognadas fue de 2.3+1,1, la moda = 2 y la mediana = 1.54.
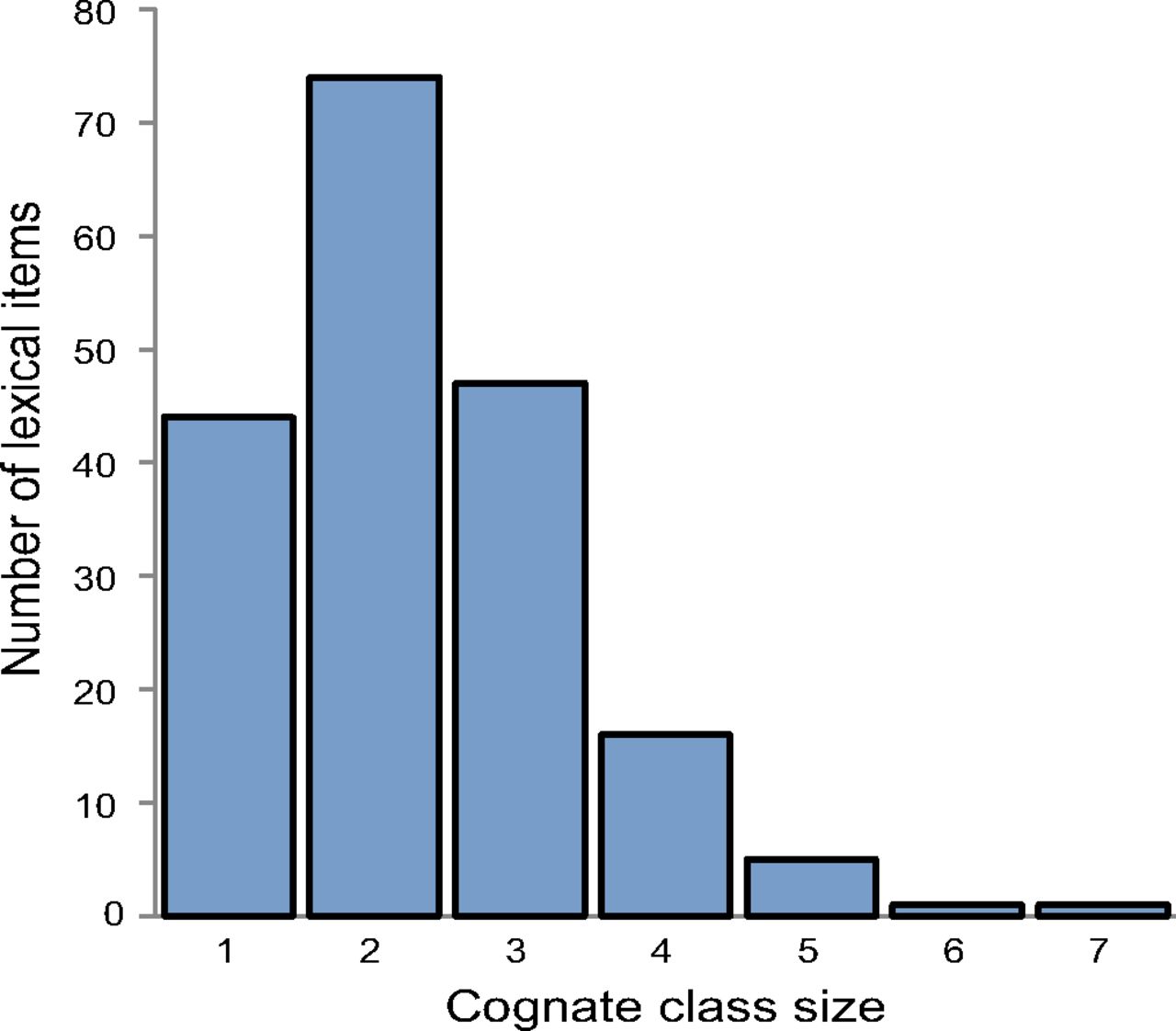
Número de familias en las que aparecen las protopalabras que corresponden a los 188 significados analizados (clases de tamaño de las cognadas). El tamaño mínimo es 1, cuando una forma solo aparece en una familia y no tiene semejantes (cognadas) en otras familias, y el máximo es 7, cuando en las siete familias hay cognadas. Tamaño medio = 2,3 (SD = 1,1)
El hecho de que la clase más numerosa sea la de 2, y luego 1 y 3, quiere decir que la mayoría de las palabras tiene una vida relativamente corta. Cuando solo están presentes en una, dos o tres familias es porque han sido sustituidas en las otras. Por eso, las que están presentes en 7 familias es porque en cada una de ellas hay al menos una lengua en la que se mantiene la palabra en cuestión. Esas son las protopalabras que, en principio, deberían corresponder a las palabras “ultraconservadas”.
Por otro lado, si efectivamente eso es así, debería observarse que hay una relación entre el tamaño de clase de las cognadas (o sea, el número de familias en el que hay protopalabras emparentadas) con la tasa de sustitución, de manera que las que se sustituyen más lentamente son las que tienden a tener representantes en más familias lingüísticas. Recordemos que la tasa de sustitución se podía estimar a partir de su frecuencia de uso de cada palabra. Y efectivamente, como era de esperar, hay una relación estadísticamente significativa (r = -0,43; p<0,001) entre el tamaño de clase de las cognadas y la tasa de sustitución.
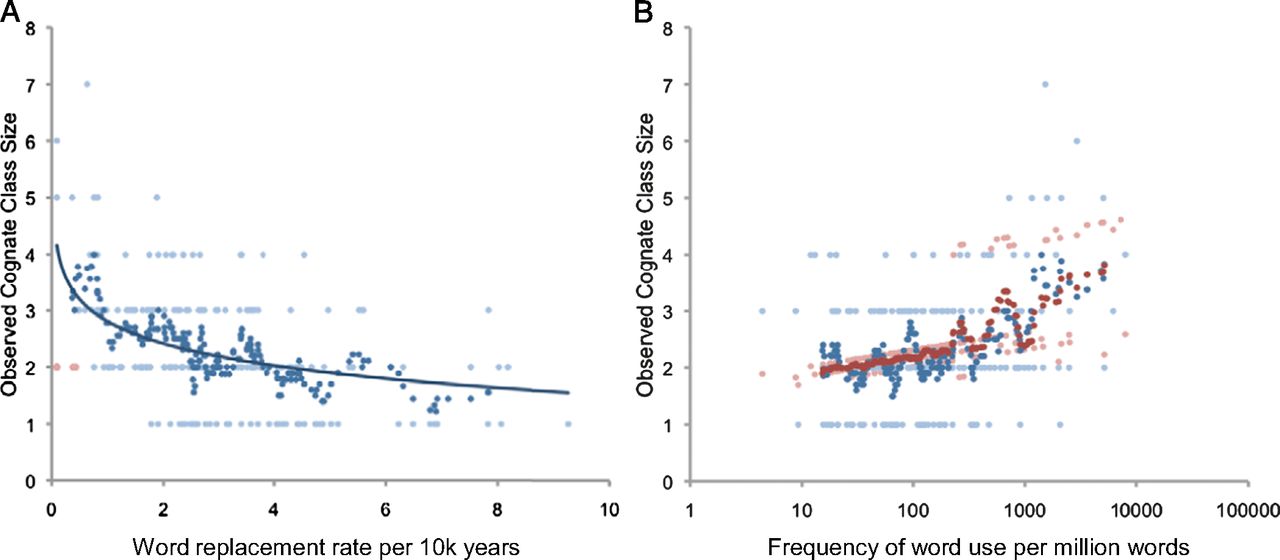
Las tasas de replazamiento o sustitución léxica (número esperado de sustituciones por otra palabra nueva no relacionada por cada 1.000 años) (A) y frecuencia de uso (número de veces que se usa una palabra por millón de palabras) (B) predicen el número de familias lingüísticas que comparten una protopalabra correspondiente a uno de los 188 significados estudiados (o clase de tamaño de las cognadas)
Las palabras que se usan más de una vez por cada 1.000 palabras en el habla cotidiana evolucionan con la suficiente lentitud como para que tengan alta probabilidad de ser cognadas en más de dos familias lingüísticas. Eso viene a equivaler a 16 usos por día y por hablante. Hay 23 significados cuyas palabras cognadas se encuentran presentes en cuatro o más familias lingüísticas (o sea, los tamaños de clase de cognadas son iguales o superiores a 4). En esa lista están sobre-representadas las palabras con una frecuencia de uso superior a una por cada 10.000.
Una vez completado el análisis anterior, los autores de la investigación estimaron un árbol filogenético de las familias lingüísticas eurasiáticas a partir de las palabras cognadas y las tasas de sustitución estimadas. Del análisis se estimó la existencia de tres grandes grupos de familias: por un lado hay un grupo de lenguas del centro y el sur de Asia, que agrupa a las lenguas de las familias kartveliana (caucásicas meridionales) y drávida; por el otro, están las familias del norte y oeste de Europa, que incluye a las lenguas indoeuropeas y urálicas, y, por último, el grupo de familias orientales, que contiene las lenguas altaicas, las esquimo-aleutianas (inuit-yupik), y las chucoto-camchatcas.
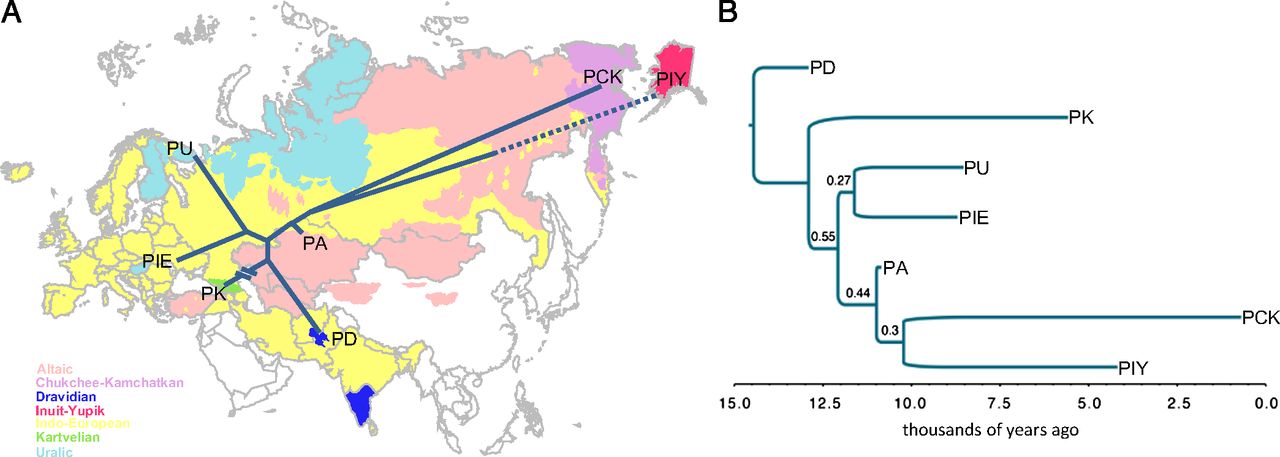
Arbol filogenético sin raíz (A) y con raíz (B). En este segundo se incluyen las fechas estimadas del origen de la superfamilia y de las familias. PD: proto-dravínica; PK: protokartveliana; PU: protourálica; PIE: protoindoeuropea; PA: protoaltaica; PCK: proto chucoto-camchatca; PIY: protoinuit-ypik
Los autores del trabajo proponen dos posibles orígenes temporales para este grupo de familias de lenguas eurasiáticas; uno de ellos estaría ubicado hace 14.450 + 1.750 años (en un intervalo de confianza que va de 11.720 a 18.380 años) y el otro, hace 15.610 + 2.290 años (en un intervalo de confianza que va de 11.720 a 20.400 años). Lógicamente, se trata de estimaciones, y muy aproximadas además, con lo que ello supone, pero si tenemos en cuenta que el último periodo glaciar terminó hace unos 15.000 años, parece lógico pensar que este conjunto de lenguas empezó a expandirse y diversificarse después de la retirada de los hielos y antes del advenimiento del Neolítico con el desarrollo de la agricultura hace unos 11.000 años.
—————————————————————————————————-
Anexo: Veintitrés palabras con tamaños de clase de semejantes iguales o superiores a cuatro entre las familias de lenguas de Eurasia
|
Familias que comparten protopalabra (nº) (*) |
Tasa de sustitución (**) |
Vida media (***) (miles de años) |
Frecuencia de uso (****) |
|
| Tú |
7 |
0.064 |
10.83 |
2,524 |
| Yo |
6 |
0.009 |
77 |
4,332 |
| No |
5 |
0.082 |
8.45 |
7,602 |
| Que |
5 |
0.188 |
3.69 |
5,846 |
| Nosotros |
5 |
0.037 |
18.73 |
2,956 |
| Dar |
5 |
0.076 |
9.12 |
1,606 |
| Quien |
5 |
0.009 |
77 |
1,172 |
| Este/a |
4 |
0.218 |
3.18 |
11,185 |
| Qué |
4 |
0.069 |
10.04 |
3,058 |
| Hombre |
4 |
0.338 |
2.05 |
2,800 |
| Vosotros |
4 |
0.132 |
5.25 |
1,459 |
| Viejo/a |
4 |
0.253 |
2.74 |
746 |
| Madre |
4 |
0.236 |
2.94 |
717 |
| Oír |
4 |
0.235 |
2.95 |
680 |
| Mano |
4 |
0.082 |
8.45 |
658 |
| Fuego |
4 |
0.175 |
3.96 |
398 |
| (Es)tirar |
4 |
0.453 |
1.71 |
279 |
| Negro |
4 |
0.191 |
3.62 |
135 |
| Fluir |
4 |
0.340 |
2.04 |
91 |
| Ladrido |
4 |
0.379 |
1.82 |
49 |
| Cenizas |
4 |
0.265 |
2.62 |
23 |
| Escupir |
4 |
0.204 |
3.38 |
23 |
| Gusano |
4 |
0.216 |
3.19 |
21 |
* Número de familias lingüísticas en las que perduran palabras que comparten una misma protopalabra (origen común). ** Número esperado de veces que se producirá una sustitución de la palabra que corresponde a un significado, por otra palabra no relacionada por cada mil años. *** Tiempo esperado hasta que la probabilidad de que una palabra sea sustituida por otra de diferente origen alcance el 50%. **** Número de veces que se usa la palabra por millón.
Fuente: Mark Pagel, Quentin D. Atkinson, Andreea S. Calude, y Andrew Meade (2013): Ultraconserved words point to deep language ancestry across Eurasia PNAS 110 (21): 8471-8476
